
Routinetätigkeiten
Netzaufbau
Netzaufbau
Das rekurrente Netz von Botvinick und Plaut (2004) stellte ein Simple Recurrent Network (SRN). dar, wobei dieses aus drei verschiedenen Schichten bestand (siehe Abbildung 26):
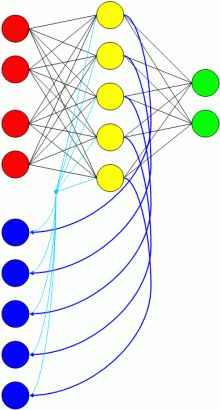
- Abbildung 26: Schematische Darstellung eines SRNs zur Simulation von Routinetätigkeiten. Aus Gründen der Übersichtlichkeit werden Verbindungen von den Kontext- zu den Hidden-Units zurück 'gebündelt' dargestellt.
- Input-Schicht:: Die Input-Schicht umfasste 39 Einheiten, wovon 20 Units verwendet wurden, um ein bestimmtes Objekt (z.B. Tasse oder Teebeutel) zu betrachten, während die verbleibenden 19 Einheiten angaben, welches Objekt aktuell mit der Hand festgehalten wurde.
- Hidden-Schicht:: Es kamen insgesamt 50 Hidden-Neuronen zum Einsatz, die vollständig mit den Einheiten der Input- und Output-Schicht verbunden waren.
- Output-Schicht:: In der Output-Schicht fanden sich 19 Units, die verschiedene Handlungen wie beispielsweise das Eingießen oder Umrühren einer Flüssigkeit repräsentierten. Die Tätigkeiten sollten an dem Gegenstand durchgeführt werden, der sich im Zentrum der Aufmerksamkeit befand (siehe Input-Schicht).
Dieses Netz (siehe Abbildung 26) sollte den Erwerb und die Durchführung der beiden Tätigkeiten "Kaffee und Tee kochen" simulieren. Damit das Netz wusste, welche der beiden Handlungen durchgeführt werden sollte, verwendete man zwei Input-Units als "Instruktionseinheiten" (Kaffee kochen vs. Tee kochen). In Abhängigkeit der durchzuführenden Tätigkeit wurde zu Beginn des Verarbeitungsprozesses eine der beiden Instruktionseinheiten einmalig aktiviert und verharrte danach in einem inaktiven Zustand, bis die gesamte Tätigkeit beendet und eine Neue begonnen wurde.
In der Trainingsphase wurden die berechneten Output-Werte mit den Korrekten verglichen (supervised learning) und die Gewichte mit Hilfe der "Backpropagation-through-time" Lernregel angepasst (Botvinick und Plaut, 2004). Zu beachten ist, dass der generierte Output teilweise als Eingabe der Input-Units für den nachfolgenden Schritt fungierte. Somit hätte man in Abbildung 26 auch die Output-Units noch mit den Input-Units verbinden können.
